Developers Guide¶
Intended Audience¶
This guide is for developers of IntelMQ. It explains the code architecture, coding guidelines as well as ways you can contribute code or documentation. If you have not done so, please read the Introduction first. Once you feel comfortable running IntelMQ with open source bots and you feel adventurous enough to contribute to the project, this guide is for you. It does not matter if you are an experienced Python programmer or just a beginner. There are a lot of samples to help you out.
However, before we go into the details, it is important to observe and internalize some overall project goals.
Goals¶
It is important, that all developers agree and stick to these meta-guidelines. IntelMQ tries to:
Be well tested. For developers this means, we expect you to write unit tests for bots. Every time.
Reduce the complexity of system administration
Reduce the complexity of writing new bots for new data feeds
Make your code easily and pleasantly readable
Reduce the probability of events lost in all process with persistence functionality (even system crash)
Strictly adhere to the existing Data Format for key-values in events
Always use JSON format for all messages internally
Help and support the interconnection between IntelMQ and existing tools like AbuseHelper, CIF, etc. or new tools (in other words: we will not accept data-silos!)
Provide an easy way to store data into Log Collectors like ElasticSearch, Splunk
Provide an easy way to create your own black-lists
Provide easy to understand interfaces with other systems via HTTP RESTFUL API
The main take away point from the list above is: things MUST stay __intuitive__ and __easy__. How do you ultimately test if things are still easy? Let them new programmers test-drive your features and if it is not understandable in 15 minutes, go back to the drawing board.
Similarly, if code does not get accepted upstream by the main developers, it is usually only because of the ease-of-use argument. Do not give up , go back to the drawing board, and re-submit again.
Development Environment¶
Installation¶
Developers can create a fork repository of IntelMQ in order to commit the new code to this repository and then be able to do pull requests to the main repository. Otherwise you can just use the ‘certtools’ as username below.
The following instructions will use pip3 -e, which gives you a so called editable installation. No code is copied in the libraries directories, there’s just a link to your code. However, configuration files still required to be moved to /opt/intelmq as the instructions show.
The traditional way to work with IntelMQ is to install it globally and have a separated user for running it. If you wish to separate your machine Python’s libraries, e.g. for development purposes, you could alternatively use a Python virtual environment and your local user to run IntelMQ. Please use your preferred way from instructions below.
Directories explained¶
For development purposes, you need two directories: one for a local repository copy, and the second as a root dictionary for the IntelMQ installation.
The default IntelMQ root directory is /opt/intelmq. This directory is used for configurations (/opt/intelmq/etc), local states (/opt/intelmq/var/lib) and logs (/opt/intelmq/var/log). If you want to change it, please set the INTELMQ_ROOT_DIR environment variable with a desired location.
For repository directory, you can use any path that is accessible by users you use to run IntelMQ. For globally installed IntelMQ, the directory has to be readable by other unprivileged users (e.g. home directories on Fedora can’t be read by other users by default).
To keep commands in the guide universal, we will use environmental variables for repository and installation paths. You can set them with following commands:
# Adjust paths if you want to use non-standard directories
export INTELMQ_REPO=/opt/dev_intelmq
export INTELMQ_ROOT_DIR=/opt/intelmq
Note
If using non-default installation directory, remember to keep the root directory variable set for every run of IntelMQ commands. If you don’t, then the default location /opt/intelmq will be used.
Using globally installed IntelMQ¶
sudo -s
git clone https://github.com/<your username>/intelmq.git $INTELMQ_REPO
cd $INTELMQ_REPO
pip3 install -e .
useradd -d $INTELMQ_ROOT_DIR -U -s /bin/bash intelmq
intelmqsetup
Using virtual environment¶
git clone https://github.com/<your username>/intelmq.git $INTELMQ_REPO
cd $INTELMQ_REPO
python -m venv .venv
source .venv/bin/activate
pip install -e .
# If you use a non-local directory as INTELMQ_ROOT_DIR, use following
# command to create it and change the ownership.
sudo install -g `whoami` -o `whoami` -d $INTELMQ_ROOT_DIR
# For local directory, just create it with mkdir:
mkdir $INTELMQ_ROOT_DIR
intelmqsetup --skip-ownership
Note
Please do not forget that configuration files, log files will be available on $INTELMQ_ROOT_DIR. However, if your development is somehow related to any shipped configuration file, you need to apply the changes in your repository $INTELMQ_REPO/intelmq/etc/.
Additional services¶
Some features require additional services, like message queue or database. The commonly used services are gained for development purposes in the Docker Compose file in contrib/development-tools/docker-compose-common-services.yaml in the repository. You can use them to run services on your machine in a docker containers, or decide to configure them in an another way. To run them using Docker Compose, use following command from the main repository directory:
# For older Docker versions, you may need to use `docker-compose` command
docker compose -f contrib/development-tools/docker-compose-common-services.yaml up -d
This will start in the background containers with Redis, RabbitMQ, PostgreSQL and MongoDB.
How to develop¶
After you successfully setup your IntelMQ development environment, you can perform any development on any .py file on $INTELMQ_REPO. After you change, you can use the normal procedure to run the bots:
su - intelmq # Use for global installation
source .venv/bin/activate # Use for virtual environment installation
intelmqctl start spamhaus-drop-collector
tail -f $INTELMQ_ROOT_DIR/var/log/spamhaus-drop-collector.log
You can also add new bots, creating the new .py file on the proper directory inside cd $INTELMQ_REPO/intelmq. However, your IntelMQ installation with pip3 needs to be updated. Please check the following section.
Update¶
In case you developed a new bot, you need to update your current development installation. In order to do that, please follow this procedure:
Make sure that you have your new bot in the right place.
Update pip metadata and new executables:
sudo -s # Use for global installation
source .venv/bin/activate # Use for virtual environment installation
cd /opt/dev_intelmq
pip3 install -e .
If you’re using the global installation, an additional step of changing permissions and ownership is necessary:
find $INTELMQ_ROOT_DIR/ -type d -exec chmod 0770 {} \+
find $INTELMQ_ROOT_DIR/ -type f -exec chmod 0660 {} \+
chown -R intelmq.intelmq $INTELMQ_ROOT_DIR
## if you use the intelmq manager (adapt the webservers' group if needed):
chown intelmq.www-data $INTELMQ_ROOT_DIR/etc/*.conf
Now you can test run your new bot following this procedure:
su - intelmq # Use for global installation
source .venv/bin/activate # Use for virtual environment installation
intelmqctl start <bot_id>
Testing¶
Libraries required for tests are listed in the setup.py file. You can install them with pip:
pip3 install -e .[development]
or the package management of your operating system.
All changes have to be tested and new contributions should be accompanied by according unit tests. Please do not run the tests as root just like any other IntelMQ component for security reasons. Any other unprivileged user is possible.
You can run the tests by changing to the directory with IntelMQ repository and running either unittest or pytest. For virtual environment installation, please activate it and omit the sudo -u from examples below:
cd $INTELMQ_REPO
sudo -u intelmq python3 -m unittest {discover|filename} # or
sudo -u intelmq pytest [filename]
sudo -u intelmq python3 setup.py test # uses a build environment (no external dependencies)
Some bots need local databases to succeed. If you only want to test one explicit test file, give the file path as argument.
There are multiple GitHub Action Workflows setup for automatic testing, which are triggered on pull requests. You can also easily activate them for your forks.
There are a bunch of environment variables which switch on/off some tests:
INTELMQ_TEST_DATABASES: databases such as postgres, elasticsearch, mongodb are not tested by default. Set this environment variable to 1 to test those bots. These tests need preparation, e.g. running databases with users and certain passwords etc. Have a look at the .github/workflows/unittests.yml and the corresponding .github/workflows/scripts/setup-full.sh in IntelMQ’s repository for steps to set databases up.
INTELMQ_SKIP_INTERNET: tests requiring internet connection will be skipped if this is set to 1.
INTELMQ_SKIP_REDIS: redis-related tests are ran by default, set this to 1 to skip those.
INTELMQ_TEST_EXOTIC: some bots and tests require libraries which may not be available, those are skipped by default. To run them, set this to 1.
INTELMQ_TEST_REDIS_PASSWORD: Set this value to the password for the local redis database if needed.
INTELMQ_LOOKYLOO_TEST: Set this value to run the lookyloo tests. Public lookyloo instance will be used as default.
INTELMQ_TEST_INSTALLATION: Set this value to run tests which require a local IntelMQ installation, such as for testing the command lines tools relying on configuration files, dump files etc.
For example, to run all tests you can use:
INTELMQ_TEST_DATABASES=1 INTELMQ_TEST_EXOTIC=1 INTELMQ_TEST_INSTALLATION=1 pytest intelmq/tests/
The tests use the configuration files in your working directory, not those installed in /opt/intelmq/etc/ or /etc/. You can run the tests for a locally changed intelmq without affecting an installation or requiring root to run them.
Development Guidelines¶
Coding-Rules¶
Most important: KEEP IT SIMPLE!! This can not be over-estimated. Feature creep can destroy any good software project. But if new folks can not understand what you wrote in 10-15 minutes, it is not good. It’s not about the performance, etc. It’s about readability.
In general, we follow PEP 0008. We recommend reading it before committing code.
There are some exceptions: sometimes it does not make sense to check for every PEP8 error (such as whitespace indentation when you want to make a dict=() assignment look pretty. Therefore, we do have some exceptions defined in the setup.cfg file.
We support Python 3 only.
Each internal object in IntelMQ (Event, Report, etc) that has strings, their strings MUST be in UTF-8 Unicode format.
Any data received from external sources MUST be transformed into UTF-8 Unicode format before add it to IntelMQ objects.
Any component of the IntelMQ MUST be independent of the message queue technology (Redis, RabbitMQ, etc…).
Please add a license and copyright header to your bots. There is a Github action that tests for reuse compliance of your code files.
Layout Rules¶
intelmq/
lib/
bot.py
cache.py
message.py
pipeline.py
utils.py
bots/
collector/
<bot name>/
collector.py
parser/
<bot name>/
parser.py
expert/
<bot name>/
expert.py
output/
<bot name>/
output.py
/conf
runtime.yaml
Assuming you want to create a bot for a new ‘Abuse.ch’ feed. It turns out that here it is necessary to create different parsers for the respective kind of events (e.g. malicious URLs). Therefore, the usual hierarchy ‘intelmq/bots/parser/<FEED>/parser.py’ would not be suitable because it is necessary to have more parsers for each Abuse.ch Feed. The solution is to use the same hierarchy with an additional “description” in the file name, separated by underscore. Also see the section Directories and Files naming.
Example (including the current ones):
/intelmq/bots/parser/abusech/parser_domain.py
/intelmq/bots/parser/abusech/parser_ip.py
/intelmq/bots/parser/abusech/parser_ransomware.py
/intelmq/bots/parser/abusech/parser_malicious_url.py
Please document your added/modified code.
For doc strings, we are using the sphinx-napoleon-google-type-annotation.
Additionally, Python’s type hints/annotations are used, see PEP 484.
Configuration Files Path: /opt/intelmq/etc/
PID Files Path: /opt/intelmq/var/run/
Logs Files and dumps Path: /opt/intelmq/var/log/
Additional Bot Files Path, e.g. templates or databases: /opt/intelmq/var/lib/bots/[bot-name]/
Any directory and file of IntelMQ has to follow the Directories and Files naming. Any file name or folder name has to * be represented with lowercase and in case of the name has multiple words, the spaces between them must be removed or replaced by underscores; * be self-explaining what the content contains.
In the bot directories name, the name must correspond to the feed provider. If necessary and applicable the feed name can and should be used as postfix for the filename.
Examples:
intelmq/bots/parser/taichung/parser.py
intelmq/bots/parser/cymru/parser_full_bogons.py
intelmq/bots/parser/abusech/parser_ransomware.py
Class name of the bot (ex: PhishTank Parser) must correspond to the type of the bot (ex: Parser) e.g. PhishTankParserBot
IntelMQ Data Format Rules¶
Any component of IntelMQ MUST respect the IntelMQ Data Format.
Reference: IntelMQ Data Format - Data Format
Code Submission Rules¶
The main repository is in github.com/certtools/intelmq.
There are a couple of forks which might be regularly merged into the main repository. They are independent and can have incompatible changes and can deviate from the upstream repository.
We use semantic versioning. A short summary: * a.x are stable releases * a.b.x are bugfix/patch releases * a.x must be compatible to version a.0 (i.e. API/Config-compatibility)
If you contribute something, please fork the repository, create a separate branch and use this for pull requests, see section below.
“master” is the stable branch. It hold the latest stable release. Non-developers should only work on this branch. The recommended log level is WARNING. Code is only added by merges from the maintenance branches.
“maintenance/a.b.x” branches accumulate (cherry-picked) patches for a maintenance release (a.b.x). Recommended for experienced users which deploy intelmq themselves. No new features will be added to these branches.
“develop” is the development branch for the next stable release (a.x). New features must go there. Developers may want to work on this branch. This branch also holds all patches from maintenance releases if applicable. The recommended log level is DEBUG.
Separate branches to develop features or bug fixes may be used by any contributor.
Make separate pull requests / branches on GitHub for changes. This allows us to discuss things via GitHub.
We prefer one Pull Request per feature or change. If you have a bunch of small fixes, please don’t create one RP per fix :)
Only very small and changes (docs, …) might be committed directly to development branches without Pull Request by the core-team.
Keep the balance between atomic commits and keeping the amount of commits per PR small. You can use interactive rebasing to squash multiple small commits into one (rebase -i [base-branch]). Only do rebasing if the code you are rebasing is yet not used by others or is already merged - because then others may need to run into conflicts.
Make sure your PR is merge able in the develop branch and all tests are successful.
If possible sign your commits with GPG.
We assume here, that origin is your own fork. We first add the upstream repository:
> git remote add upstream https://github.com/certtools/intelmq.git
Syncing develop:
> git checkout develop
> git pull upstream develop
> git push origin develop
You can do the same with the branches master and maintenance.
Create a separate feature-branch to work on, sync develop with upstream. Create working branch from develop:
> git checkout develop
> git checkout -b bugfix
# your work
> git commit
Or, for bugfixes create a separate bugfix-branch to work on, sync maintenance with upstream. Create working branch from maintenance:
> git checkout maintenance
> git checkout -b new-feature
# your work
> git commit
Getting upstream’s changes for master or any other branch:
> git checkout develop
> git pull upstream develop
> git push origin develop
There are 2 possibilities to get upstream’s commits into your branch. Rebasing and Merging. Using rebasing, your history is rewritten, putting your changes on top of all other commits. You can use this if your changes are not published yet (or only in your fork).
> git checkout bugfix
> git rebase develop
Using the -i flag for rebase enables interactive rebasing. You can then remove, reorder and squash commits, rewrite commit messages, beginning with the given branch, e.g. develop.
Or using merging. This doesn’t break the history. It’s considered more , but also pollutes the history with merge commits.
> git checkout bugfix
> git merge develop
You can then create a PR with your branch bugfix to our upstream repository, using GitHub’s web interface.
If it fixes an existing issue, please use GitHub syntax, e.g.: fixes certtools/intelmq#<IssueID>
If we don’t discuss it, it’s probably not tested.
System Overview¶
In the intelmq/lib/ directory you can find some libraries:
Bots: Defines base structure for bots and handling of startup, stop, messages etc.
Cache: For some expert bots it does make sense to cache external lookup results. Redis is used here.
Harmonization: For defined types, checks and sanitation methods are implemented.
Message: Defines Events and Reports classes, uses harmonization to check validity of keys and values according to config.
Pipeline: Writes messages to message queues. Implemented for productions use is only Redis, AMQP is beta.
Test: Base class for bot tests with predefined test and assert methods.
Utils: Utility functions used by system components.
Code Architecture¶
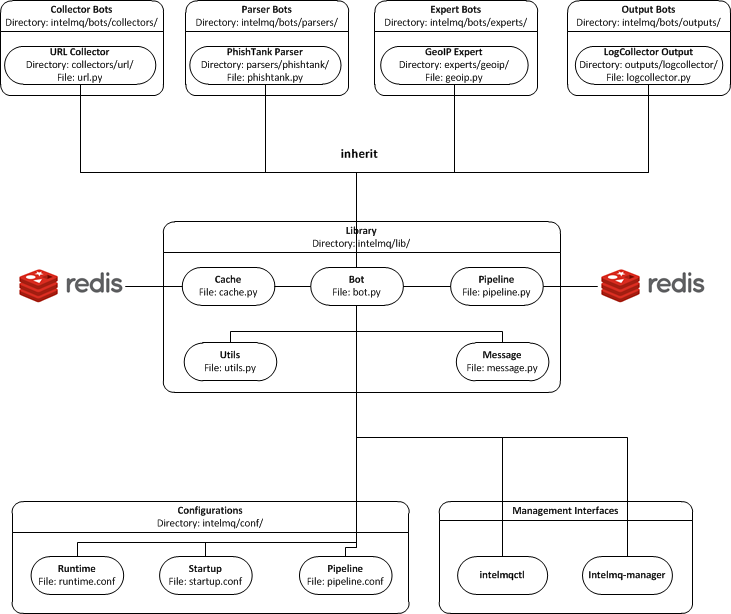
Pipeline¶
collector bot
TBD
Bot Developer Guide¶
There’s a dummy bot including tests at intelmq/tests/lib/test_parser_bot.py.
Please use the correct bot type as parent class for your bot. The intelmq.lib.bot module contains the classes CollectorBot, ParserBot, ExpertBot and OutputBot.
You can always start any bot directly from command line by calling the executable. The executable will be created during installation a directory for binaries. After adding new bots to the code, install IntelMQ to get the files created. Don’t forget to give an bot id as first argument. Also, running bots with other users than intelmq will raise permission errors.
$ sudo -i intelmq
$ intelmqctl run file-output # if configured
$ intelmq.bots.outputs.file.output file-output
You will get all logging outputs directly on stderr as well as in the log file.
Template¶
Please adjust the doc strings accordingly and remove the in-line comments (#).
"""
SPDX-FileCopyrightText: 2021 Your Name
SPDX-License-Identifier: AGPL-3.0-or-later
Parse data from example.com, be a nice ExampleParserBot.
Document possible necessary configurations.
"""
import sys
# imports for additional libraries and intelmq
from intelmq.lib.bot import ParserBot
class ExampleParserBot(ParserBot):
option1: str = "defaultvalue"
option2: bool = False
def process(self):
report = self.receive_message()
event = self.new_event(report) # copies feed.name, time.observation
... # implement the logic here
event.add('source.ip', '127.0.0.1')
event.add('extra', {"os.name": "Linux"})
if self.option2:
event.add('extra', {"customvalue": self.option1})
self.send_message(event)
self.acknowledge_message()
BOT = ExampleParserBot
Any attributes of the bot that are not private can be set by the user using the IntelMQ configuration settings.
There are some names with special meaning. These can be used i.e. called:
stop: Shuts the bot down.
receive_message, send_message, acknowledge_message: see next section
start: internal method to run the bot
These can be defined:
init: called at startup, use it to set up the bot (initializing classes, loading files etc)
process: processes the messages
shutdown: To Gracefully stop the bot, e.g. terminate connections
All other names can be used freely.
Mixins¶
For common settings and methods you can use mixins from intelmq.lib.mixins. To use the mixins, just let your bot inherit from the Mixin class (in addition to the inheritance from the Bot class). For example:
class HTTPCollectorBot(CollectorBot, HttpMixin):
The following mixins are available:
HttpMixin
SqlMixin
CacheMixin
The HttpMixin provides the HTTP attributes described in Common parameters and the following methods:
http_gettakes an URL as argument. Any other arguments get passed to therequest.Session.getmethod.http_getreturns arequests.Response.http_sessioncan be used if you ever want to work with the session object directly. It takes no arguments and returns the bots request.Session.
The SqlMixin provides methods to connect to SQL servers. Inherit this Mixin so that it handles DB connection for you. You do not have to bother:
connecting database in the
self.init()method, self.cur will be set in the__init__()catching exceptions, just call
self.execute()instead ofself.cur.execute()self.format_charwill be set to ‘%s’ in PostgreSQL and to ‘?’ in SQLite
The CacheMixin provides methods to cache values for bots in a Redis database. It uses the following attributes:
redis_cache_host: str = "127.0.0.1"redis_cache_port: int = 6379redis_cache_db: int = 9redis_cache_ttl: int = 15redis_cache_password: Optional[str] = None
and provides the methods:
cache_existscache_getcache_setcache_flushcache_get_redis_instance
Pipeline interactions¶
We can call three methods related to the pipeline:
self.receive_message(): The pipeline handler pops one message from the internal queue if possible. Otherwise one message from the sources list is popped, and added it to an internal queue. In case of errors in process handling, the message can still be found in the internal queue and is not lost. The bot class unravels the message a creates an instance of the Event or Report class.
self.send_message(event, path=”_default”): Processed message is sent to destination queues. It is possible to change the destination queues by optional path parameter.
self.acknowledge_message(): Message formerly received by receive_message is removed from the internal queue. This should always be done after processing and after the sending of the new message. In case of errors, this function is not called and the message will stay in the internal queue waiting to be processed again.
Logging¶
Log messages have to be clear and well formatted. The format is the following:
Format:
<timestamp> - <bot id> - <log level> - <log message>
Rules:
the Log message MUST follow the common rules of a sentence, beginning with uppercase and ending with period.
the sentence MUST describe the problem or has useful information to give to an inexperienced user a context. Pure stack traces without any further explanation are not helpful.
When the logger instance is created, the bot id must be given as parameter anyway. The function call defines the log level, see below.
debug: Debugging information includes retrieved and sent messages, detailed status information. Can include sensitive information like passwords and amount can be huge.
info: Logs include loaded databases, fetched reports or waiting messages.
warning: Unexpected, but handled behavior.
error: Errors and Exceptions.
critical Program is failing.
Try to keep a balance between obscuring the source code file with hundreds of log messages and having too little log messages.
In general, a bot MUST report error conditions.
The Bot class creates a logger with that should be used by bots. Other components won’t log anyway currently. Examples:
The exception method automatically appends an exception traceback. The logger instance writes by default to the file /opt/intelmq/var/log/[bot-id].log and to stderr.
Parameters for string formatting are better passed as argument to the log function, see https://docs.python.org/3/library/logging.html#logging.Logger.debug In case of formatting problems, the error messages will be better. For example:
Error handling¶
The bot class itself has error handling implemented. The bot itself is allowed to throw exceptions and intended to fail! The bot should fail in case of malicious messages, and in case of unavailable but necessary resources. The bot class handles the exception and will restart until the maximum number of tries is reached and fail then. Additionally, the message in question is dumped to the file /opt/intelmq/var/log/[bot-id].dump and removed from the queue.
Initialization¶
Maybe it is necessary so setup a Cache instance or load a file into memory. Use the init function for this purpose:
Custom configuration checks¶
Every bot can define a static method check(parameters) which will be called by intelmqctl check. For example the check function of the ASNLookupExpert:
Examples¶
Check Expert Bots
Check Parser Bots
Parsers¶
Parsers can use a different, specialized Bot-class. It allows to work on individual elements of a report, splitting the functionality of the parser into multiple functions:
process: getting and sending data, handling of failures etc.
parse: Parses the report and splits it into single elements (e.g. lines). Can be overridden.
parse_line: Parses elements, returns an Event. Can be overridden.
recover_line: In case of failures and for the field raw, this function recovers a fully functional report containing only one element. Can be overridden.
For common cases, like CSV, existing function can be used, reducing the amount of code to implement. In the best case, only parse_line needs to be coded, as only this part interprets the data.
You can have a look at the implementation intelmq/lib/bot.py or at examples, e.g. the DummyBot in intelmq/tests/lib/test_parser_bot.py. This is a stub for creating a new Parser, showing the parameters and possible code:
One line can lead to multiple events, thus parse_line can’t just return one Event. Thus, this function is a generator, which allows to easily return multiple values. Use yield event for valid Events and return in case of a void result (not parsable line, invalid data etc.).
Tests¶
In order to do automated tests on the bot, it is necessary to write tests including sample data. Have a look at some existing tests:
The DummyParserBot in intelmq/tests/lib/test_parser_bot.py. This test has the example data (report and event) inside the file, defined as dictionary.
The parser for malwaregroup at intelmq/tests/bots/parsers/malwaregroup/test_parser_*.py. The latter loads a sample HTML file from the same directory, which is the raw report.
The test for ASNLookupExpertBot has two event tests, one is an expected fail (IPv6).
Ideally an example contains not only the ideal case which should succeed, but also a case where should fail instead. (TODO: Implement assertEventNotEqual or assertEventNotcontainsSubset or similar) Most existing bots are only tested with one message. For newly written test it is appreciable to have tests including more then one message, e.g. a parser fed with an report consisting of multiple events.
When calling the file directly, only the tests in this file for the bot will be expected. Some default tests are always executed (via the test.BotTestCase class), such as pipeline and message checks, logging, bot naming or empty message handling.
See the Testing Pre-releases section about how to run the tests.
Cache¶
Bots can use a Redis database as cache instance. Use the intelmq.lib.utils.Cache class to set this up and/or look at existing bots, like the cymru_whois expert how the cache can be used. Bots must set a TTL for all keys that are cached to avoid caches growing endless over time. Bots must use the Redis databases >= 10, but not those already used by other bots. Look at find intelmq -type f -name ‘*.py’ -exec grep -r ‘redis_cache_db’ {} + to see which databases are already used.
- The databases < 10 are reserved for the IntelMQ core:
2: pipeline
3: statistics
4: tests
Documentation¶
The documentation is automatically published to https://intelmq.readthedocs.io/ at every push to the repository.
To build the documentation you need three packages: - Sphinx - ReCommonMark - sphinx-markdown-tables
To install them, you can use pip:
pip3 install -r docs/requirements.txt
Then use the Makefile to build the documentation using Sphinx:
cd docs
make html
Feeds documentation¶
The feeds which are known to be working with IntelMQ are documented in the machine-readable file intelmq/etc/feeds.yaml. The human-readable documentation is in generated with the Sphinx build as described in the previous section.
Testing Pre-releases¶
Installation¶
The installation procedures need to be adapted only a little bit.
For native packages, you can find the unstable packages of the next version here: Installation Unstable Native Packages. The unstable only has a limited set of packages, so enabling the stable repository can be activated in parallel. For CentOS 8 unstable, the stable repository is required.
For the installation with pip, use the –pre parameter as shown here following command:
pip3 install --pre intelmq
All other steps are not different. Please report any issues you find in our Issue Tracker.