Configuration and Management¶
For installation instructions, see Installation. For upgrade instructions, see Upgrade instructions.
Configure services¶
You need to enable and start Redis if not already done. Using systemd it can be done with:
systemctl enable redis.service
systemctl start redis.service
Configuration¶
/opt and LSB paths¶
If you installed the packages, standard Linux paths (LSB paths) are used: /var/log/intelmq/, /etc/intelmq/, /var/lib/intelmq/, /var/run/intelmq/.
Otherwise, the configuration directory is /opt/intelmq/etc/. Using the environment variable INTELMQ_ROOT_DIR allows setting any arbitrary root directory.
You can switch this by setting the environment variables INTELMQ_PATHS_NO_OPT and INTELMQ_PATHS_OPT, respectively.
* When installing the Python packages, you can set INTELMQ_PATHS_NO_OPT to something non-empty to use LSB-paths.
* When installing the deb/rpm packages, you can set INTELMQ_PATHS_OPT to something non-empty to use /opt/intelmq/ paths, or a path set with INTELMQ_ROOT_DIR.
The environment variable ROOT_DIR is meant to set an alternative root directory instead of /. This is primarily meant for package build environments an analogous to setuptools’ --root parameter. Thus it is only used in LSB-mode.
Overview¶
The main configuration file is formatted in the YAML format since IntelMQ 3.0 (before it was JSON, which had some downsides). Although, comments in YAML are currently not preserved by IntelMQ (known bug #2003). For new installations a default setup with some examples is provided by the intelmqsetup tool. If this is not the case, make sure the program was run (see Installation instructions).
runtime.yaml: Configuration for the individual bots. See Bots inventory for more details.harmonization.conf: Configuration of the internal data format, see Data Format and Harmonization field names.
To configure a new bot, you need to define and configure it in runtime.yaml.
You can base your configuration on the output of intelmqctl list bots and the Data Feeds documentation page.
Use the IntelMQ Manager mentioned above to generate the configuration files if unsure.
In the shipped examples 4 collectors and parsers, 6 common experts and one output are configured. The default collector and the parser handle data from malware domain list, the file output bot writes all data to /opt/intelmq/var/lib/bots/file-output/events.txt//var/lib/intelmq/bots/file-output/events.txt.
Systemwide Configuration (global)¶
All bots inherit the global configuration parameters in the runtime.yaml and they can overwrite them using the same parameters in their individual configuration in the runtime.yaml file.
Logging¶
The logging can be configured with the following parameters:
logging_handler: Can be one of"file"or"syslog".logging_level: Defines the system-wide log level that will be use by all bots and the intelmqctl tool. Possible values are:"CRITICAL","ERROR","WARNING","INFO"and"DEBUG".logging_path: Iflogging_handlerisfile. Defines the system-wide log-folder that will be use by all bots and the intelmqctl tool. Default value:/opt/intelmq/var/log/or/var/log/intelmq/respectively.logging_syslog: Iflogging_handlerissyslog. Either a list with hostname and UDP port of syslog service, e.g.["localhost", 514]or a device name/path, e.g. the default"/var/log".
We recommend logging_level WARNING for production environments and INFO if you want more details. In any case, watch your free disk space!
Log rotation¶
To rotate the logs, you can use the standard Linux-tool logrotate.
An example logrotate configuration is given in contrib/logrotate/ and delivered with all deb/rpm-packages.
When not using logrotate, IntelMQ can rotate the logs itself, which is not enabled by default! You need to set both values.
logging_max_size: Maximum number of bytes to be stored in one logfile before the file is rotated (default: 0, equivalent to unset).logging_max_copies: Maximum number of logfiles to keep (default: unset). Compression is not supported.
Some information can as well be found in Python’s documentation on the used RotatingFileHandler.
Error Handling¶
- error_log_message - in case of an error, this option will allow the bot to write the message (report or event) to the log file. Use the following values:
true/false - write or not write message to the log file
- error_log_exception - in case of an error, this option will allow the bot to write the error exception to the log file. Use the following values:
true/false - write or not write exception to the log file
error_procedure - in case of an error, this option defines the procedure that the bot will adopt. Use the following values:
stop - stop bot after retrying X times (as defined in
error_max_retries) with a delay between retries (as defined inerror_retry_delay). If the bot reaches theerror_max_retriesvalue, it will remove the message from the pipeline and stop. If the optionerror_dump_messageis also enable, the bot will dump the removed message to its dump file (to be found in var/log).pass - will skip this message and will process the next message after retrying X times, removing the current message from pipeline. If the option
error_dump_messageis also enable, then the bot will dump the removed message to its dump file. After max retries are reached, the rate limit is applied (e.g. a collector bot fetch an unavailable resource does not try forever).
error_max_retries - in case of an error, the bot will try to re-start processing the current message X times as defined by this option. int value.
error_retry_delay - defines the number of seconds to wait between subsequent re-tries in case of an error. int value.
- error_dump_message - specifies if the bot will write queued up messages to its dump file (use intelmqdump to re-insert the message).
true/false - write or not write message to the dump file
If the path _on_error exists for a bot, the message is also sent to this queue, instead of (only) dumping the file if configured to do so.
Miscellaneous¶
- load_balance - this option allows you to choose the behavior of the queue. Use the following values:
true - splits the messages into several queues without duplication
false - duplicates the messages into each queue
When using AMQP as message broker, take a look at the Multithreading (Beta) section and the
instances_threadsparameter.
rate_limit - time interval (in seconds) between messages processing. int value.
ssl_ca_certificate - trusted CA certificate for IMAP connections (supported by some bots).
- source_pipeline_broker & destination_pipeline_broker - select which broker IntelMQ should use. There are two options
redis (default) - Please note that persistence has to be manually activated.
amqp - The AMQP pipeline is currently beta but there are no known issues. A popular AMQP broker is RabbitMQ. See AMQP (Beta) for more details.
As these parameters can be set per bot, this allows usage of different broker systems and hosts, as well as switching between them on the same IntelMQ instance.
source_pipeline_host - broker IP, FQDN or Unix socket that the bot will use to connect and receive messages.
source_pipeline_port - broker port that the bot will use to connect and receive messages. Can be empty for Unix socket.
source_pipeline_password - broker password that the bot will use to connect and receive messages. Can be null for unprotected broker.
source_pipeline_db - broker database that the bot will use to connect and receive messages (requirement from redis broker).
destination_pipeline_host - broker IP, FQDN or Unix socket that the bot will use to connect and send messages.
destination_pipeline_port - broker port that the bot will use to connect and send messages. Can be empty for Unix socket.
destination_pipeline_password - broker password that the bot will use to connect and send messages. Can be null for unprotected broker.
destination_pipeline_db - broker database that the bot will use to connect and send messages (requirement from redis broker).
http_proxy - HTTP proxy the that bot will use when performing HTTP requests (e.g. bots/collectors/collector_http.py). The value must follow RFC 1738.
https_proxy - HTTPS proxy that the bot will use when performing secure HTTPS requests (e.g. bots/collectors/collector_http.py).
http_user_agent - user-agent string that the bot will use when performing HTTP/HTTPS requests (e.g. bots/collectors/collector_http.py).
- http_verify_cert - defines if the bot will verify SSL certificates when performing HTTPS requests (e.g. bots/collectors/collector_http.py).
true/false - verify or not verify SSL certificates
Using supervisor as process manager (Beta)¶
First of all: Do not use it in production environments yet! It has not been tested thoroughly yet.
Supervisor is process manager written in Python. The main advantage is that it take care about processes, so if bot process exit with failure (exit code different than 0), supervisor try to run it again. Another advantage is that it not require writing PID files.
This was tested on Ubuntu 18.04.
Install supervisor. supervisor_twiddler is extension for supervisor, that makes possible to create process dynamically. (Ubuntu supervisor package is currently based on Python 2, so supervisor_twiddler must be installed with Python 2 pip.)
apt install supervisor python-pip
pip install supervisor_twiddler
Create default config /etc/supervisor/conf.d/intelmq.conf and restart supervisor service:
[rpcinterface:twiddler]
supervisor.rpcinterface_factory=supervisor_twiddler.rpcinterface:make_twiddler_rpcinterface
[group:intelmq]
Change IntelMQ process manager in the global configuration:
process_manager: supervisor
After this it is possible to manage bots like before with intelmqctl command.
Runtime Configuration¶
This configuration is used by each bot to load its specific (runtime) parameters. The IntelMQ Manager can generate this configuration for you. You may edit it manually as well. Be sure to re-load the bot (see the intelmqctl documentation).
Template:
<bot ID>:
group: <bot type (Collector, Parser, Expert, Output)>
name: <human-readable bot name>
module: <bot code (python module)>
description: <generic description of the bot>
parameters:
<parameter 1>: <value 1>
<parameter 2>: <value 2>
<parameter 3>: <value 3>
Example:
blocklistde-apache-collector:
group: Collector
name: Blocklist.de Apache List
module: intelmq.bots.collectors.http.collector_http
description: Blocklist.de Apache Collector fetches all IP addresses which have been reported within the last 48 hours as having run attacks on the service Apache, Apache-DDOS, RFI-Attacks.
parameters:
http_url: https://lists.blocklist.de/lists/apache.txt
name: Blocklist.de Apache
rate_limit: 3600
More examples can be found in the intelmq/etc/runtime.yaml file. See Bots inventory for more details.
By default, all of the bots are started when you start the whole botnet, however there is a possibility to disable a bot. This means that the bot will not start every time you start the botnet, but you can start and stop the bot if you specify the bot explicitly. To disable a bot, add the following to your runtime.yaml: "enabled": false. For example:
blocklistde-apache-collector:
group: Collector
name: Blocklist.de Apache List
module: intelmq.bots.collectors.http.collector_http
description: Blocklist.de Apache Collector fetches all IP addresses which have been reported within the last 48 hours as having run attacks on the service Apache, Apache-DDOS, RFI-Attacks.
enabled: false
parameters:
http_url: https://lists.blocklist.de/lists/apache.txt
name: Blocklist.de Apache
rate_limit: 3600
Pipeline Configuration¶
The pipeline configuration defines how the data is exchanges between the bots. For each bot, it defines the source queue (there is always only one) and one or multiple destination queues. This section shows the possibilities and definition as well as examples. The configuration of the pipeline can be done by the IntelMQ Manager with no need to intervene manually. It is recommended to use this tool as it guarantees that the configuration is correct. The configuration of the pipelines is done in the runtime.yaml as part of the individual bots settings.
Source queue¶
This setting is optional, by default, the source queue is the bot ID plus “-queue” appended.
For example, if the bot ID is example-bot, the source queue name is example-bot-queue.
source-queue: example-bot-queue
For collectors, this field does not exist, as the fetch the data from outside the IntelMQ system by definition.
Destination queues¶
Destination queues are defined using a dictionary with a name as key and a list of queue-identifiers as the value.
destination-queues:
_default:
- <first destination pipeline name>
- <second destination pipeline name>
_on_error:
- <optional first destination pipeline name in case of errors>
- <optional second destination pipeline name in case of errors>
other-path:
- <second destination pipeline name>
- <third destination pipeline name>
In this case, bot will be able to send the message to one of defined paths. The path "_default" is used if none is specified by the bot itself.
In case of errors during processing, and the optional path "_on_error" is specified, the message will be sent to the pipelines given given as on-error.
Other destination queues can be explicitly addressed by the bots, e.g. bots with filtering capabilities. Some expert bots are capable of sending messages to paths, this feature is explained in their documentation, e.g. the Filter expert and the Sieve expert.
The named queues need to be explicitly addressed by the bot (e.g. filtering) or the core (_on_error) to be used. Setting arbitrary paths has no effect.
AMQP (Beta)¶
Starting with IntelMQ 1.2 the AMQP protocol is supported as message queue. To use it, install a broker, for example RabbitMQ. The configuration and the differences are outlined here. Keep in mind that it is slower, but has better monitoring capabilities and is more stable. The AMQP support is considered beta, so small problems might occur. So far, only RabbitMQ as broker has been tested.
You can change the broker for single bots (set the parameters in the runtime configuration per bot) or for the whole botnet (using the global configuration).
You need to set the parameter source_pipeline_broker/destination_pipeline_broker to amqp. There are more parameters available:
destination_pipeline_broker:"amqp"destination_pipeline_host(default:'127.0.0.1')destination_pipeline_port(default: 5672)destination_pipeline_usernamedestination_pipeline_passworddestination_pipeline_socket_timeout(default: no timeout)destination_pipeline_amqp_exchange: Only change/set this if you know what you do. If set, the destination queues are not declared as queues, but used as routing key. (default:'').destination_pipeline_amqp_virtual_host(default:'/')source_pipeline_host(default:'127.0.0.1')source_pipeline_port(default: 5672)source_pipeline_usernamesource_pipeline_passwordsource_pipeline_socket_timeout(default: no timeout)source_pipeline_amqp_exchange: Only change/set this if you know what you do. If set, the destination queues are not declared as queues, but used as routing key. (default: ‘’).source_pipeline_amqp_virtual_host(default:'/')intelmqctl_rabbitmq_monitoring_urlstring, see below (default:"http://{host}:15672")
For getting the queue sizes, intelmqctl needs to connect to the monitoring interface of RabbitMQ. If the monitoring interface is not available under http://{host}:15672 you can manually set using the parameter intelmqctl_rabbitmq_monitoring_url.
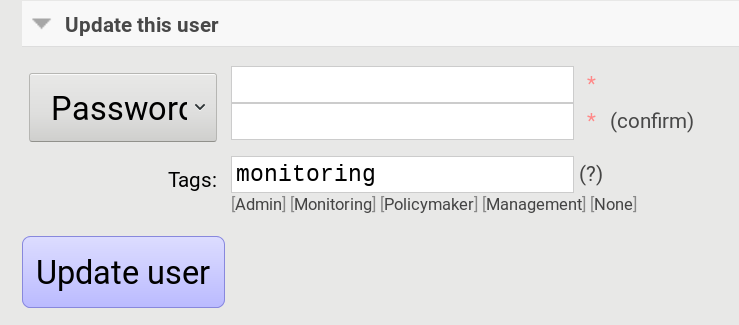
In a RabbitMQ’s default configuration you might not provide a user account, as by default the administrator (guest:guest) allows full access from localhost. If you create a separate user account, make sure to add the tag “monitoring” to it, otherwise IntelMQ can’t fetch the queue sizes.
Setting the statistics (and cache) parameters is necessary when the local redis is running under a non-default host/port. If this is the case, you can set them explicitly:
statistics_database:3statistics_host:"127.0.0.1"statistics_password:nullstatistics_port:6379
Multithreading (Beta)¶
First of all: Do not use it in production environments yet! There are a few bugs, see below
Since IntelMQ 2.0 it is possible to provide the following parameter:
instances_threads
Set it to a non-zero integer, then this number of worker threads will be spawn. This is useful if bots often wait for system resources or if network-based lookups are a bottleneck.
However, there are currently a few cavecats:
This is not possible for all bots, there are some exceptions (collectors and some outputs), see the Frequently asked questions for some reasons.
Only use it with the AMQP pipeline, as with Redis, messages may get duplicated because there’s only one internal queue
In the logs, you can see the main thread initializing first, then all of the threads which log with the name
[bot-id].[thread-id].
Harmonization Configuration¶
This configuration is used to specify the fields for all message types. The harmonization library will load this configuration to check, during the message processing, if the values are compliant to the “harmonization” format. Usually, this configuration doesn’t need any change. It is mostly maintained by the intelmq maintainers.
Template:
{
"<message type>": {
"<field 1>": {
"description": "<field 1 description>",
"type": "<field value type>"
},
"<field 2>": {
"description": "<field 2 description>",
"type": "<field value type>"
}
},
}
Example:
{
"event": {
"destination.asn": {
"description": "The autonomous system number from which originated the connection.",
"type": "Integer"
},
"destination.geolocation.cc": {
"description": "Country-Code according to ISO3166-1 alpha-2 for the destination IP.",
"regex": "^[a-zA-Z0-9]{2}$",
"type": "String"
},
},
}
More examples can be found in the intelmq/etc/harmonization.conf directory.
Utilities¶
Management¶
IntelMQ has a modular structure consisting of bots. There are four types of bots:
Collector Bots retrieve data from internal or external sources, the output are reports consisting of many individual data sets / log lines.
Parser Bots parse the (report) data by splitting it into individual events (log lines) and giving them a defined structure, see also Data Format for the list of fields an event may be split up into.
Expert Bots enrich the existing events by e.g. lookup up information such as DNS reverse records, geographic location information (country code) or abuse contacts for an IP address or domain name.
Output Bots write events to files, databases, (REST)-APIs or any other data sink that you might want to write to.
Each bot has one source queue (except collectors) and can have multiple destination queues (except outputs). But multiple bots can write to the same pipeline (queue), resulting in multiple inputs for the next bot.
Every bot runs in a separate process. A bot is identifiable by a bot id.
Currently only one instance (i.e. with the same bot id) of a bot can run at the same time. Concepts for multiprocessing are being discussed, see this issue: Multiprocessing per queue is not supported #186. Currently you can run multiple processes of the same bot (with different bot ids) in parallel.
Example: multiple gethostbyname bots (with different bot ids) may run in parallel, with the same input queue and sending to the same output queue. Note that the bot providing the input queue must have the load_balance option set to true.
Web interface: IntelMQ Manager¶
IntelMQ has a tool called IntelMQ Manager that gives users an easy way to configure all pipelines with bots that your team needs. For beginners, it’s recommended to use the IntelMQ Manager to become acquainted with the functionalities and concepts. The IntelMQ Manager offers some of the possibilities of the intelmqctl tool and has a graphical interface for runtime and pipeline configurations.
See the IntelMQ Manager repository.
Command-line interface: intelmqctl¶
Syntax see intelmqctl -h
Starting a bot:
intelmqctl start bot-idStopping a bot:
intelmqctl stop bot-idReloading a bot:
intelmqctl reload bot-idRestarting a bot:
intelmqctl restart bot-idGet status of a bot:
intelmqctl status bot-idRun a bot directly for debugging purpose and temporarily leverage the logging level to DEBUG:
intelmqctl run bot-idGet a pdb (or ipdb if installed) live console.
intelmqctl run bot-id consoleSee the message that waits in the input queue.
intelmqctl run bot-id message getSee additional help for further explanation.
intelmqctl run bot-id --helpStarting the botnet (all bots):
intelmqctl startStarting a group of bots:
intelmqctl start --group expertsGet a list of all configured bots:
intelmqctl list botsGet a list of all queues:
intelmqctl list queuesIf -q is given, only queues with more than one item are listed.Get a list of all queues and status of the bots:
intelmqctl list queues-and-statusClear a queue:
intelmqctl clear queue-idGet logs of a bot:
intelmqctl log bot-id number-of-lines log-levelReads the last lines from bot log. Log level should be one of DEBUG, INFO, ERROR or CRITICAL. Default is INFO. Number of lines defaults to 10, -1 gives all. Result can be longer due to our logging format!Upgrade from a previous version:
intelmqctl upgrade-configMake a backup of your configuration first, also including bot’s configuration files.
Botnet Concept¶
The “botnet” represents all currently configured bots which are explicitly enabled. It is, in essence, the graph of the bots which are connected together via their input source queues and destination queues.
To get an overview which bots are running, use intelmqctl status or use the IntelMQ Manager. Set "enabled": true in the runtime configuration to add a bot to the botnet. By default, bots will be configured as "enabled": true. See Bots inventory for more details on configuration.
Disabled bots can still be started explicitly using intelmqctl start <bot_id>, but will remain in the state disabled if stopped (and not be implicitly enabled by the start command). They are not started by intelmqctl start in analogy to the behavior of widely used initialization systems.
Scheduled Run Mode¶
In many cases, it is useful to schedule a bot at a specific time (i.e. via cron(1)), for example to collect information from a website every day at midnight. To do this, set run_mode to scheduled in the runtime.yaml for the bot. Check out the following example:
blocklistde-apache-collector:
name: Generic URL Fetcher
group: Collector
module: intelmq.bots.collectors.http.collector_http
description: All IP addresses which have been reported within the last 48 hours as having run attacks on the service Apache, Apache-DDOS, RFI-Attacks.
enabled: false
run_mode: scheduled
parameters:
feed: Blocklist.de Apache
provider: Blocklist.de
http_url: https://lists.blocklist.de/lists/apache.txt
ssl_client_certificate: null
You can schedule the bot with a crontab-entry like this:
0 0 * * * intelmqctl start blocklistde-apache-collector
Bots configured as scheduled will exit after the first successful run.
Setting enabled to false will cause the bot to not start with intelmqctl start, but only with an explicit start, in this example intelmqctl start blocklistde-apache-collector.
Continuous Run Mode¶
Most of the cases, bots will need to be configured as continuous run mode (the default) in order to have them always running and processing events. Usually, the types of bots that will require the continuous mode will be Parsers, Experts and Outputs. To do this, set run_mode to continuous in the runtime.yaml for the bot. Check the following example:
blocklistde-apache-parser:
name: Blocklist.de Parser
group: Parser
module: intelmq.bots.parsers.blocklistde.parser
description: Blocklist.DE Parser is the bot responsible to parse the report and sanitize the information.
enabled: false
run_mode: continuous
parameters: ...
You can now start the bot using the following command:
intelmqctl start blocklistde-apache-parser
Bots configured as continuous will never exit except if there is an error and the error handling configuration requires the bot to exit. See the Error Handling section for more details.
Reloading¶
Whilst restart is a mere stop & start, performing intelmqctl reload <bot_id> will not stop the bot, permitting it to keep the state: the same common behavior as for (Linux) daemons. It will initialize again (including reading all configuration again) after the current action is finished. Also, the rate limit/sleep is continued (with the new time) and not interrupted like with the restart command. So if you have a collector with a rate limit of 24 h, the reload does not trigger a new fetching of the source at the time of the reload, but just 24 h after the last run – with the new configuration.
Which state the bots are keeping depends on the bots of course.
Forcing reset pipeline and cache (be careful)¶
If you are using the default broker (Redis), in some test situations you may need to quickly clear all pipelines and caches. Use the following procedure:
redis-cli FLUSHDB
redis-cli FLUSHALL
Error Handling¶
Tool: intelmqdump¶
When bots are failing due to bad input data or programming errors, they can dump the problematic message to a file along with a traceback, if configured accordingly. These dumps are saved at in the logging directory as [botid].dump as JSON files. IntelMQ comes with an inspection and reinjection tool, called intelmqdump. It is an interactive tool to show all dumped files and the number of dumps per file. Choose a file by bot-id or listed numeric id. You can then choose to delete single entries from the file with e 1,3,4, show a message in more readable format with s 1 (prints the raw-message, can be long!), recover some messages and put them back in the pipeline for the bot by a or r 0,4,5. Or delete the file with all dumped messages using d.
intelmqdump -h
usage:
intelmqdump [botid]
intelmqdump [-h|--help]
intelmqdump can inspect dumped messages, show, delete or reinject them into
the pipeline. It's an interactive tool, directly start it to get a list of
available dumps or call it with a known bot id as parameter.
positional arguments:
botid botid to inspect dumps of
optional arguments:
-h, --help show this help message and exit
--truncate TRUNCATE, -t TRUNCATE
Truncate raw-data with more characters than given. 0 for no truncating. Default: 1000.
Interactive actions after a file has been selected:
- r, Recover by IDs
> r id{,id} [queue name]
> r 3,4,6
> r 3,7,90 modify-expert-queue
The messages identified by a consecutive numbering will be stored in the
original queue or the given one and removed from the file.
- a, Recover all
> a [queue name]
> a
> a modify-expert-queue
All messages in the opened file will be recovered to the stored or given
queue and removed from the file.
- d, Delete entries by IDs
> d id{,id}
> d 3,5
The entries will be deleted from the dump file.
- d, Delete file
> d
Delete the opened file as a whole.
- s, Show by IDs
> s id{,id}
> s 0,4,5
Show the selected IP in a readable format. It's still a raw format from
repr, but with newlines for message and traceback.
- e, Edit by ID
> e id
> e 0
> e 1,2
Opens an editor (by calling `sensible-editor`) on the message. The modified message is then saved in the dump.
- q, Quit
> q
$ intelmqdump
id: name (bot id) content
0: alienvault-otx-parser 1 dumps
1: cymru-whois-expert 8 dumps
2: deduplicator-expert 2 dumps
3: dragon-research-group-ssh-parser 2 dumps
4: file-output2 1 dumps
5: fraunhofer-dga-parser 1 dumps
6: spamhaus-cert-parser 4 dumps
7: test-bot 2 dumps
Which dump file to process (id or name)? 3
Processing dragon-research-group-ssh-parser: 2 dumps
0: 2015-09-03T13:13:22.159014 InvalidValue: invalid value u'NA' (<type 'unicode'>) for key u'source.asn'
1: 2015-09-01T14:40:20.973743 InvalidValue: invalid value u'NA' (<type 'unicode'>) for key u'source.asn'
(r)ecover by ids, recover (a)ll, delete (e)ntries, (d)elete file, (s)how by ids, (q)uit, edit id (v)? d
Deleted file /opt/intelmq/var/log/dragon-research-group-ssh-parser.dump
Bots and the intelmqdump tool use file locks to prevent writing to already opened files. Bots are trying to lock the file for up to 60 seconds if the dump file is locked already by another process (intelmqdump) and then give up. Intelmqdump does not wait and instead only shows an error message.
By default, the show command truncates the raw field of messages at 1000 characters to change this limit or disable truncating at all (value 0), use the --truncate parameter.
Monitoring Logs¶
All bots and intelmqctl log to /opt/intelmq/var/log//var/log/intelmq/ (depending on your installation). In case of failures, messages are dumped to the same directory with the file ending .dump.
tail -f /opt/intelmq/var/log/*.log
tail -f /var/log/intelmq/*.log
Uninstall¶
If you installed intelmq with native packages: Use the package management tool to remove the package intelmq. These tools do not remove configuration by default.
If you installed manually via pip (note that this also deletes all configuration and possibly data):
pip3 uninstall intelmq
rm -r /opt/intelmq
Integration with ticket systems, etc.¶
First of all, IntelMQ is a message (event) processing system: it collects feeds, processes them, enriches them, filters them and then stores them somewhere or sends them to another system. It does this in a composable, data flow oriented fashion, based on single events. There are no aggregation or grouping features. Now, if you want to integrate IntelMQ with your ticket system or some other system, you need to send its output to somewhere where your ticket system or other services can pick up IntelMQ’s data. This could be a database, splunk, or you could send your events directly via email to a ticket system.
- Different users came up with different solutions for this, each of them fitting their own organisation. Hence these solutions are not part of the core IntelMQ repository.
CERT.at uses a postgresql DB (sql output bot) and has a small tool
intelmqcliwhich fetches the events in the postgresql DB which are marked as “new” and will group them and send them out via the RT ticket system.Others, including BSI, use a tool called
intelmq-mailgen. It sends E-Mails to the recipients, optionally PGP-signed with defined text-templates, CSV formatted attachments with grouped events and generated ticket numbers.
The following lists external github repositories which you might consult for examples on how to integrate IntelMQ into your workflow:
If you came up with another solution for integration, we’d like to hear from you! Please reach out to us on the IntelMQ Users Mailinglist.
Frequently Asked Questions¶
Consult the Frequently asked questions if you encountered any problems.
Additional Information¶
Bash Completion¶
To enable bash completion on intelmqctl and intelmqdump in order to help you run the commands in an easy manner, follow the installation process here.